Transaction
Transaction is a series of queries
It’s the unit of operation
Non-devisible, either all queries executed, either none
Important way to maintain consistency and data integrity
BEGIN TRANSACTION SELECT * FROM A COMMIT; ROLLBACK;
Atomicity
- The transaction is indivisible
- Rollback when failed
The Atomicity is achived by Undo Log
- Undo log stores the reversve operation logic with every queries
- Undo log is stored in the different table space
- It will mainly record the value and operation
- If a ROLLBACK invoked, the data is able to be restored by undo-log
Consistency
Consistency refers to data consistency and read consistency
- Data Consistency means the data can be cross valided by different logfic on different places.
- Read Consistency means no lag in reading data?
Consistency is the goal, A, I, and D are the approaches.
Isolation
- Isolation is the key feaures to ensure the concurrency while not affecting data consistency and integrety
4 scenarios that needs to be optimised by different level of isolations
- Read-Read: No affect
- Write-Write: Two transactions writing on the same field. Add Lock
- Read-Write: Read-write scenarios will results in a lot of issues if not setting the isolation level properly. It will lead: Dirty Read, Un-repeatable Read and Phantom read.
Different lock in Read-read:
By Lock mode:
Exclusive lock (X)
- Other transaction are not allowed any read/write operations on the locked row
START TRANSACTION; UPDATE table_name SET column1 = 'value' WHERE id = 1; -- X锁加在id=1的行上 UPDATE table_name SET column1 = 'value' WHERE id = 1 FOR UPDATE; -- 显式上X锁加在id=1的行上 UPDATE table_name SET column1 = '1' WHERE id = '1' FOR UPDATE SELECT column1 FROM table_name where id = '2' FOR UPDATESELECT ... FOR UPDATE:对特定记录加X锁。UPDATE/DELETE/INSERT:自动加X锁。LOCK TABLE ... IN EXCLUSIVE MODE:对整张表加X锁。- Release after commit or rollback
Shared Lock (S)
Ensure the read row is read-only
SELECT column1, column2 FROM table_name WHERE condition FOR SHARE; SELECT column1 FROM table_name WHERE id = 'a' LOCK IN SHARE MODERelease after commit or rollback
Intend lock (IS or IX)
- It is applied on a page level;
- This is for indicating a transaction is intends to set a S/X lock on individual row level, to prevent the potential conflicts
- For example:
- Transaction A, Row A has a S lock
- Table AA will be added with an IS lock automatically
- When Transaction B is going to add an X lock on Table AA before A is committed, it will block
Update Lock (U)
Avoid the dead lock when two transaction want to update the same target while the raw has added S lock by both of the transaction
Example:
BEGIN; SELECT * FROM orders WHERE id = 1 WITH (UPDLOCK); -- 加 U锁 -- 决定更新数据,U锁升级为 X锁 UPDATE orders SET status = 'processed' WHERE id = 1; COMMIT; BEGIN; SELECT * FROM orders WHERE id = 1 WITH (UPDLOCK); -- 加 U锁,被阻塞直到事务A完成 -- 决定更新数据 UPDATE orders SET status = 'canceled' WHERE id = 1; COMMIT;
Dead Lock Example:
- 事务A对某行加S锁。
- 事务B对同一行加S锁。
- 事务A尝试将S锁升级为X锁,但需要等待事务B释放S锁。
- 事务B也尝试将S锁升级为X锁,但需要等待事务A释放S锁.
- 结果:事务A和事务B相互等待,发生死锁。
Record Lock
Gap Lock
Next Key Lock
How to optimise the concurrency in Read-Write Scenarios
- Different isolation level:
- Read uncommited: The in-flight transaction can read the uncommited change.
- Read commited: The in-flight transaction can read the commited change only .It avoids the dirty read
- Repeatable read: The in-flight transaction can only read the transaction that’s been commited before the current transaction. It avoids the dirty read and unrepeatable read.
- Serilizable Only one transaction is permitted at a moment.
Read Committed and Repeated Read is achived by Multi-version Concurrency Control (MVCC)
- Three Important components of MVCC:
- Hidden Fields: Transaction ID and Roll back pointer
- The readview
- The Undo log chain
- By comparing the current transaction id and the trasnaction id in the undo log chain
Durability
The Durability is achievd by Redo Log
- Every transaction will be write in Redo Log.
- Redo log stored in the ROM
- Transaction applied on the buffer pool
- buffer pool flashes the datafile on ROM regularly
A complete process of executing a transaction
- Transaction Begin
- Lookingfor or Loading the data in the Buffer Pool
- Record the operations on Undo Log
- Update the Memory Data: Including Buffer Pool and Redo Log Buffer
- Write the Redo Log on disk drive
- Commit the transaction
- Record all operations of the transaction in BinLog
- The changed value on buffer pool will be flashed to disk regularly
Index
Why Do We Need an Index?
- Without an index, searching for a specific row in a table involves scanning all rows sequentially, resulting in a time complexity of O(n) for read operations.
- Indexing accelerates query performance by enabling faster lookups, particularly in large datasets.
How data stored in DB
- Logically, they are stored as rows and columns in DB
Hash Index
What Is a Hash Index?
A hash index is a data structure that accelerates query operations by creating a mapping between key values in one or more columns of a table and their corresponding storage locations.
- How It Works:
- Hash Function
- Each key value is passed through a hash function, which transforms the key into a hash value.
- A good hash function ensures that inputs are distributed uniformly across the hash space, minimizing clustering and hash collisions.
- Bucket Mapping
- The number of buckets, mm, is determined, which represents storage divisions in memory.
- The specific bucket for a key is calculated as:Bucket Index=Hash Function(key)mod mBucket Index=Hash Function(key)modm
- Handling Hash Collisions
- Collision Definition: Two different keys may produce the same hash value, resulting in a collision.
- Collision Resolution Methods
- Chaining (Linked List): Multiple values mapped to the same bucket are stored in a linked list.
- Open Addressing: If a bucket is already occupied, an alternative bucket is located based on a probing sequence (e.g., linear probing or quadratic probing).
- Hash Function
- Storage of Hash Index:
- The hash index is typically stored in RAM for fast access.
- To ensure data durability in the event of failure, Write-Ahead Logging (WAL) or other persistence mechanisms can be used.
- Pointer to Data Rows:
- The value in a hash index is a pointer or reference to the row in the table, allowing direct access to the data.
Time Complexity of Hash Index
- Average Case: O(1)for lookups, insertions, and deletions, as hash functions provide direct access to buckets.
- Worst Case: O(n), which occurs when hash collisions lead to a single bucket storing many entries (e.g., all keys hashing to the same bucket).
Why Use a Hash Index?
- Advantages:
- Efficient Query Performance
- Hash indices provide constant-time O(1)O(1) lookups for equality-based queries (
=orIN).
- Hash indices provide constant-time O(1)O(1) lookups for equality-based queries (
- Low Memory Overhead
- Hash indices are compact and require less memory compared to tree-based indices like B-trees.
- Limitations:
- No Range Query Support
- Hash indices are unsuitable for range queries (e.g.,
<,>,BETWEEN) because hash functions do not preserve order.
- Hash indices are unsuitable for range queries (e.g.,
- Random Distribution of Keys
- Hash functions distribute keys randomly across buckets, making ordered operations (like
ORDER BY) impossible using the index.
- Hash functions distribute keys randomly across buckets, making ordered operations (like
- Collision Overhead
- Handling hash collisions adds complexity and may degrade performance in scenarios with poor hash function design or high data skew.
Additions and Enhancements
- Durability:
- While you mentioned WAL for durability, it’s worth noting that hash indices are often rebuilt after a crash if stored only in memory, making them better suited for temporary tables or volatile workloads.
- Comparison to Other Index Types:
- Compared to B-tree indices:
- Hash indices are faster for equality queries.
- B-trees are more versatile, supporting range queries, order maintenance, and prefix matching.
- Compared to B-tree indices:
- Common Use Cases:
- Hash indices are ideal for:
- Lookup tables with frequent equality queries.
- Key-value stores and in-memory databases (e.g., Redis).
- Indexing columns with unique or near-unique values.
- Hash indices are ideal for:
How to implement Hash Index
CREATE TABLE test (
id INT,
value VARCHAR(255),
PRIMARY KEY (id),
KEY(value) USING HASH
) ENGINE=Memory;
B Tree
Why do we need B-Tree
- We want to query the data in log time
What is B-Tree
- It’s a balance tree: All the leaf nodes are on the same level
- Multi-branching: With a m-order B-tree, it has
- Maximum m child nodes, minimum m/2 child nodes
- Maximum m-1 keys in one node, minimum m/2 -1 leys in one node
- (except for the root node)
- Order: Every keys are sorted in a ascending order
- The value stored on each key is the pointer pointing to the corresponding row
Insertion in B-Tree
- Starting from the root node, and navigating to the corresponding position on the leaf node. All keys in the node are sorted in the ascending order.
- If the number of keys is greater than m-1, split the node into two, and push the middle key as the father node. (anchestor node?)
Deletion in B-Tree
- Starting from the root node, and navigating to the corresponding position.
- If the deletion target is the leaf node, delete it,
- If the number of nodes after deleetion is smaller than m/2-1, take the sbling node as the new seperator in the parent node, and take the original seperator into the target leaf node
- If the sbling node is also at the minumum nodes, then we can merge the target node, the separator and the sbling node together
- If the target node is non-leaf node, we have to find an alternative key as the seprator, this could be the largest key on the left-hand child node, or the smallest key of the righ-hand side child node
I/O of B-Tree
The B-Tree is stored in hard Drive
Each time, it will read a single level of nodes into the RAM
B+ Tree
Difference from B-Tree:
- In B-Tree, the values of all nodes contains to pointer pointing to the record
- In B-Tree, only the leaf node contains the pointer pointing to the record
- m order B-tree has maximum m-1 keys in a single mode
- m order B+ tree has maximum m keys in a single mode, each key on the non-leaf node is the maximum value of it’s childern node
- B+ Tree has an additional pointer starting at the leaf node. Making it easy to do sequantial search and range query

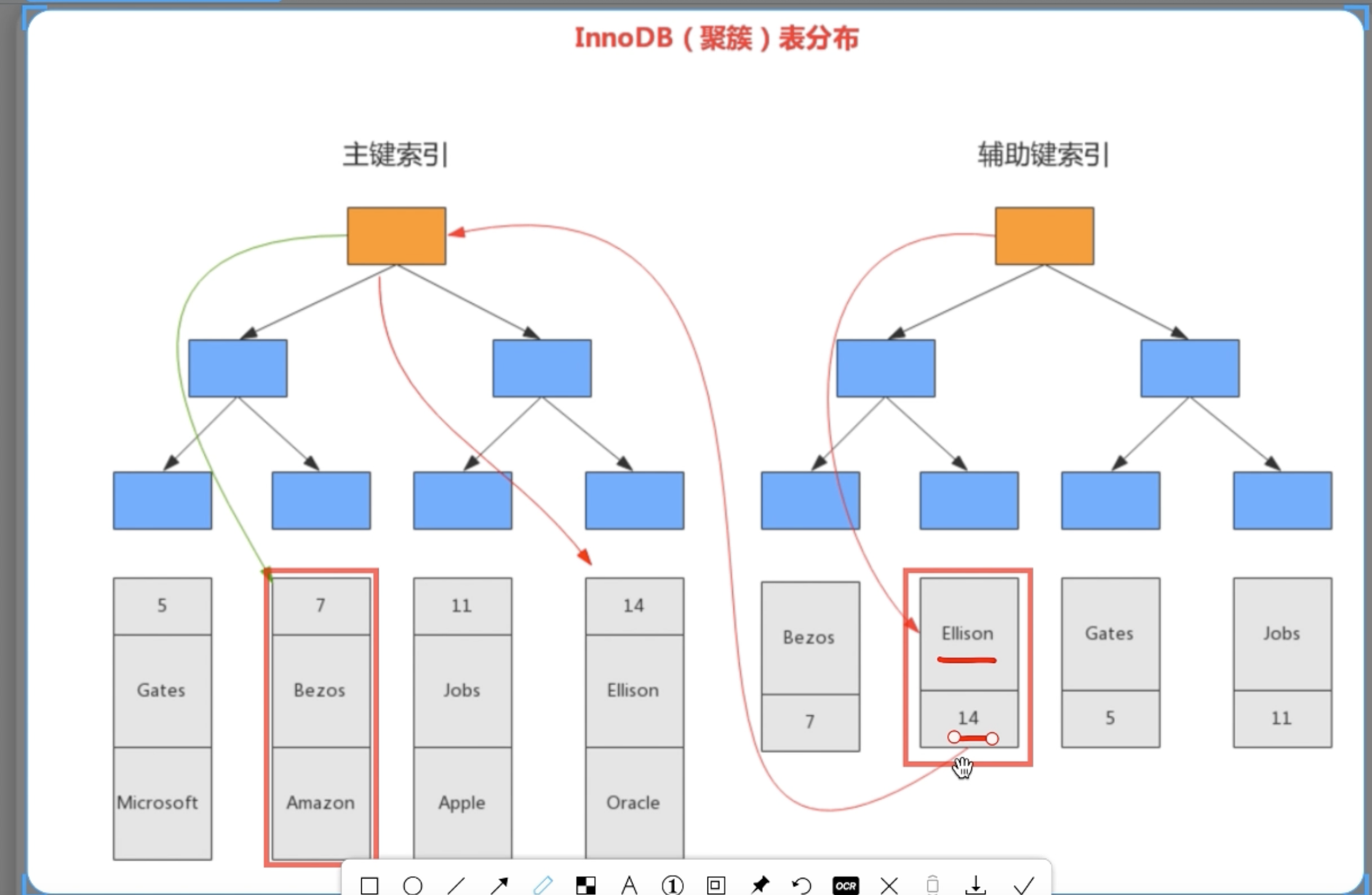
Clustered and non-clustered Index
- Note this is another dimention to describe index. The data srtrucuter is all B+ Tree by default.
- The major difference is either we put the real data or the pointer on the leaf node